
Az AI-munkaterhelések robbanásszerű növekedése alapjaiban változtatja meg az adatközponti hálózatokat. Míg a hagyományos felhőalapú architektúrák a rugalmasságra építettek, a modern mesterséges intelligencia minimális késleltetést és veszteségmentes adatátvitelt igényel. Az Arista innovatív AI-spine megoldásai, élükön a 7800R4 platformmal, választ adnak e kihívásokra: az egyedülálló skálázhatóság, az intelligens terheléselosztás és az öngyógyító fabric technológia együttesen teremtik meg az utat a jövő 1,6 Tbps sebességű, ultrahatékony AI-ökoszisztémái felé.
A leaf-spine-tól az AI-spine-ig
A mára a felhőben széleskörűen elterjedt „leaf-spine” architektúra-modellt még 2008-ban vezette be és azóta is népszerűsíti az Arista. A 7800-as moduláris platform a felhőalapú működési elvek megtestesülése – az iparágban vezető skálázhatósággal, veszteségmentességgel, ultraalacsony késleltetéssel, erőteljes megfigyelhetőséggel és beépített rezilienciával.
Ez az architektúra fejlődött tovább az egyesített (univerzális) AI-spine-ná, amely a hatalmas skálázhatóságot, a kiszámítható teljesítményt és nagysebességű interfészek támogatását biztosítja.
Az Arista 7800-as sorozat olyan erőteljes funkciókkal rendelkezik, mint a Virtual Output Queuing (VOQ), amely megszünteti a head-of-line blokkolást (amikor a sor elején várakozó csomag megakadályozza a mögötte lévő csomagok továbbítását, torlódást okoz, így csökkenti a rendszer átviteli sebességét), valamint a nagy kapacitású pufferek, amelyek elnyelik az AI-forgalmi mikrokitöréseket és megakadályozzák a PFC-viharok kialakulását.
Az AI-hálózatok átalakulása
A gyorsítóegységek (XPUs) felerősítették a hálózati igényeket, amelyek tovább nőnek és fejlődnek. A holnap AI-hálózatainak 1000-szeres vagy még nagyobb munkaterhelést kell kezelniük mind a betanulási (training), mind a következtetési (inference) határmodellek számára. A betanulásnál a legfontosabb mérőszám a feladat befejezési ideje (Job Completion Time, JCT). Az inferenciánál más a fő mérőszám: ott a token feldolgozásához szükséges idő a lényeges.
Az Arista egy olyan átfogó AI-funkciókészletet fejlesztett ki, amely lehetővé teszi az AI- és felhős munkaterhelések kiszámítható és stabil működését a változatos, hosszú és nagy volumenű adatforgalom ellenére is.
A fenti elvárásokra adott válaszában az Arista Accelerated Networking portfóliója háromféle Etherlink Spine-Leaf fabric megoldást kínál, amelyek sikeresen alkalmazhatók a hálózat méretének növelésében, kiterjesztésében és átalakításában.
AI-spine-ok a megoldás kulcsai
A gyorsítók (XPUs) robbanásszerűen növekvő sávszélesség-igénye miatt a hagyományos spine megoldások már nem elegendők, ezért megjelentek a teljesen új, kifejezetten AI-ra tervezett verziók.
Három kulcsfontosságú tényező határozza meg a növekedés mértékét:
- Keresztirányú sávszélesség növekedése: ez a hálózaton átmenő teljes áteresztőképességet jelenti. Ahogy a munkaterhelések egyre komplexebbek és elosztottabbak lesznek, a hálózati keresztmetszeti sávszélességnek az új eszközök hozzáadásával együtt egyenletesen kell növekednie, hogy elkerüljük a torlódást és megőrizzük a teljesítményt.
- Kollektív degradáció: ahogy egyre több eszközt kapcsolunk a hálózathoz, a kollektív (csoportos) kommunikáció könnyen szűk keresztmetszetté válhat. A rendszernek úgy kell működnie, hogy a teljesítmény ne essen drasztikusan, amikor egyre több csomópont vesz részt a feldolgozásban.
- Fenntartható valós XPU kihasználtság (~75%, nem 50%): a cél nem egy elméleti csúcsteljesítmény elérése, hanem az, hogy a rendszer nagyobb környezetben is folyamatosan és kiszámíthatóan működjön, valós éles körülményekhez hasonlító terhelés mellett.
Alkalmazkodás az AI-adatközpontok méretéhez
Az ultranagy léptékű AI-alkalmazások esetén, ahol egy adatközponton belül több tízezer XPU összekapcsolása szükséges – bizonyos esetekben akár 100 ezer párhuzamos XPU-val –, az Arista univerzális leaf-spine architektúrája kínálja a legegyszerűbb, legrugalmasabb és legjobban skálázható megoldást az AI-munkaterhelések támogatására.
Az Arista EOS (Extensible Operating System) intelligens, valós idejű terhelés elosztást biztosít, amely a tényleges hálózati kihasználtság figyelembevételével egyenletesen osztja el a forgalmat és elkerüli az adatfolyamok ütközését.
Fejlett telemetriai képességei – mint például az AI Analyzer és a Latency Analyzer – átlátható képet adnak a hálózati üzemeltetők számára az optimális konfigurációs küszöbértékekről, biztosítva, hogy az XPU-k a fabric-en keresztül vonalsebességű adatátvitelt érjenek el csomagvesztés nélkül.
Az AI-klaszter méretétől függően az AI leaf opciók a fix kialakítású AI-platformoktól egészen a nagy kapacitású 7800-as sorozatú moduláris platformokig terjedhetnek.
Az Arista legújabb AI spine-ja – 7800R4
Az Arista 7800R4 egy korszakváltó alternatívát kínál a hagyományos, elosztott felépítésű leaf-spine architektúrákkal szemben, amelyek tisztán L3-alapú EVPN/VXLAN fabric-re épülnek és több rack-szekrényen keresztül összekapcsolt számos különálló eszközt igényelnek.
A hibakeresés már nem egyetlen réteg vizsgálatát jelenti, hanem több vezérlési és adatforgalmi sík, valamint overlay és underlay rétegek kölcsönhatásai közötti eligazodást. Még a rutinszerű diagnosztika is időigényessé és hibalehetőségekkel terheltté válhat.
A 7800R4 AI spine platform kiküszöböli az elosztott leaf-spine kialakításokra jellemző felesleges szoftveres bonyolultságot, a megnövekedett energiafogyasztást és az üzemeltetési többletterhet. Ehelyett egy letisztultabb, integrált megoldást kínál, amely sokkal egyszerűbben vizsgálható és üzemeltethető, valamint hatékonyan csökkenti a torlódásokat, biztosítva a megbízható feladat-végrehajtási időket és a stabil teljesítményt.
A 7800 AI spine egyetlen egységes rendszerbe integrálja a vezérlési síkot, az áramellátást, a hűtést, az adatfeldolgozást és adattovábbítást, valamint a menedzsment funkciókat.
Az ügyfelek számára így egységes konfigurációs, monitorozási és diagnosztikai felület áll rendelkezésre, amely az AI-munkaterhelések egyik kulcsfontosságú igényére válaszol: egyszerű üzemeltetés, kiszámítható RDMA-teljesítménnyel, ahogy az alábbi ábrán is látható.
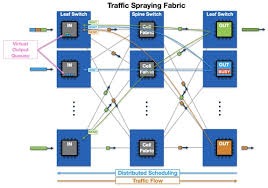
Hibatűrésre és megbízható működésre tervezve
A 7800-as fabric lényegében öngyógyító. A belső kapcsolatok, amelyek összekötik a bejövő chipet, a fabric modulokat és a kimeneti chipet, beépített gyorsítási funkcióval rendelkeznek és működés közben folyamatosan monitorozzák őket. Ha egy fabric-link hibát észlel, akkor a rendszer automatikusan eltávolítja a tervezett útvonalból, és csak akkor kerül vissza, ha helyreállt. Ez az automatizált reziliencia csökkenti az üzemeltetési terheket és biztosítja a rendszer következetes és kiszámítható működését.
A 7800-as sorozat magas rendelkezésre állásra készült, redundáns vezérlőkártyákkal, fabric kártyákkal és tápegységekkel rendelkezik. Minden fő hardverkomponens – fabric modulok, bővítő kártyák, tápegységek és felügyeleti modulok – a helyszínen cserélhetők, ami gyors hardverhiba-helyreállást és minimális szolgáltatás kiesést eredményez. Ez egy olyan átlátható és integrált megoldást kínál, amellyel a különálló eszközökből felépülő rendszerek nehezen tudnak versenyezni.
A 7800-as architektúra ütemezett VOQ fabric-et használ hierarchikus pufferezéssel, amely lehetővé teszi, hogy a csomagok hatékonyan haladjanak át a bejövő és a kimenő portok között, így elkerülhető a head-of-line blokkolás és a csomagütközés. Mivel a pufferelés a bejövő oldalon történik, a torlódás miatti csomagvesztések lokálisak és kiszámíthatók, ami jelentősen egyszerűsíti a hibák okának elemzését.
A 7800 architektúra kulcsfontosságú előnyei:
- nagy kapacitású puffer-memória, amely elnyeli a torlódásokat, így biztosítva a veszteségmentes AI-adatátvitelt;
- csomagvesztés-ellenőrzés a csomagvesztés elkerülésére;
- hierarchikus csomag-pufferezés a DCI/WAN határoknál, amely lehetővé teszi több gyártó XPU-jainak egyidejű használatát.
Megérkeztek az AI-spine-ok
A 7800-as AI Spine a központ, amely számos elosztott topológiát és klasztert kapcsol össze. Az Arista rövid idő alatt több, mint 20 darabos Etherlink switch portfóliót tervezett, amely 400 G / 800 G / 1,6 Tbps sebességet biztosít az AI-munkaterhelésekhez. A cég elkötelezett egy nyílt, egymással együttműködő AI-ökoszisztéma támogatása mellett, amely kompatibilis olyan iparágvezető vállalatokkal, mint az AMD, az Anthropic, az Arm, a Broadcom, az Nvidia, az OpenAI, a Pure Storage és a Vast Data.
Az AI-hálózatokhoz modern AI-spine-ra és olyan szoftver-stackre van szükség, amely képes az alapvető képzési és inferencia-modellek futtatására, és a tokeneket teraflopos számítási kapacitással, terabites sávszélességű hálózatokon dolgozza fel.
Üdvözöljük az AI-spine-ok és az AI-adatközpontok új korszakában!